
이 포스트에서는 앞서 배운 내용들과 pytorch에서 제공하는 optimizer를 사용하여
더 깔끔한 linear regression 코드를 작성해보도록 하겠습니다.
딥러닝 코드 작성의 4단계
stage 0 : 트레이닝에 사용할 input, output 을 설정한다.
stage 1 : Model 디자인 하기 : forward pass 를 구성한다.
stage 2 : Loss와 Optimizer 설정하기
stage 3 : Training loop 과정
a.
Forward : prediction과의 loss를 구한다
b.
Backward : gradient를 구한다
c.
weight를 update 한다
Prediction만 Manually하게 모델 만들기
import torch
import torch.nn as nn # pytorch module for loss, optimizer
# Linear regression
# f = w * x
# here : f = 2 * x
# stage 0) input, output 설정
X = torch.tensor([1, 2, 3, 4], dtype=torch.float32)
Y = torch.tensor([2, 4, 6, 8], dtype=torch.float32)
# stage 1) model 디자인하기- weight, forward pass
w = torch.tensor(0.0, dtype=torch.float32, requires_grad=True)
def forward(x):
return w * x
print(f'Prediction before training: f(5) = {forward(5).item():.3f}')
# stage 2) loss 랑 optimizer 설정하기
learning_rate = 0.01
n_iters = 100
# pytorch에서 제공하는 함수를 이용한다.
loss = nn.MSELoss()
optimizer = torch.optim.SGD([w], lr=learning_rate)
# stage 3) Training loop
for epoch in range(n_iters):
# a) forward pass
y_predicted = forward(X)
l = loss(Y, y_predicted)
# b) backward pass
l.backward()
# c) update weight
optimizer.step()
# zero the gradients after updating
optimizer.zero_grad()
if epoch % 10 == 0:
print('epoch ', epoch+1, ': w = ', w, ' loss = ', l)
print(f'Prediction after training: f(5) = {forward(5).item():.3f}')
Python
복사
 class로 제작한 모델 사용하기
class로 제작한 모델 사용하기
import torch
import torch.nn as nn
# stage 0) Input, Output 불러오기
X = torch.tensor([[1], [2], [3], [4]], dtype = torch.float32)
Y = torch.tensor([[3], [5], [7], [9]], dtype = torch.float32)
n_samples, n_features = X.shape
print(f'#samples: {n_samples}, #features: {n_features}')
# 학습된 모델을 테스트할 Input 데이터셋 준비
X_test = torch.tensor([5], dtype = torch.float32)
# stage 1) Model 구성하기 - forward pass 만들기
input_size = n_features
output_size = n_features
class LinearRegression(nn.Module):
# 모델의 기본적인 입출력 dimension을 설정한다
def __init__(self, input_dim, output_dim):
super(LinearRegression, self).__init__()
# 모델에 들어갈 여러 Layer를 선언한다
self.linear = nn.Linear(input_dim, output_dim)
def forward(self,x):
return self.linear(x)
model = LinearRegression(input_size, output_size)
print(f'Prediction before training: f(5) = {model(X_test).item():.3f}')
# stage 2) loss 랑 optimizer 설정하기
learning_rate = 0.05
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# stage 3) Training loop
n_iters = 200
for epoch in range(n_iters):
# a) Forward pass : prediction과의 loss를 구한다
y_predicted = model(X)
l = loss(Y, y_predicted)
# b) Backward pass : gradient를 구한다
l.backward()
# c) weight를 update 한다
optimizer.step()
# update 후에 gradient를 초기화 해준다
optimizer.zero_grad()
if epoch % 10 == 0:
[w,b] = model.parameters() # 구하고자 하는 weight, bias 저장하기
print('epoch ', epoch+1,'\n', ': w = ', w.item(), ': b = ', b.item(), '\nloss = ', l.item(), '\n')
print(f'Prediction after training: f(5) = {model(X_test).item():.3f}')
Python
복사
Linear Regression & Logistic Regression 예제 살펴보기
1. Linear Regression
import torch
import torch.nn as nn
import numpy as np
from sklearn import datasets # 데이터셋 제작을 위해 필요한 라이브러리
import matplotlib.pyplot as plt # 결과 plot을 위한 라이브러리
# 0) Prepare data
X_numpy, y_numpy = datasets.make_regression(n_samples=100, n_features=1, noise=10, random_state=4)
# float 타입의 텐서로 만들기
X = torch.from_numpy(X_numpy.astype(np.float32))
y = torch.from_numpy(y_numpy.astype(np.float32))
y = y.view(y.shape[0], 1)
n_samples, n_features = X.shape # (100, 1)
# 1) Model
# Linear model f = wx + b
input_size = n_features
output_size = 1
model = nn.Linear(input_size, output_size)
# 2) Loss and optimizer
learning_rate = 0.01
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 3) Training loop
num_epochs = 100
for epoch in range(num_epochs):
# Forward pass and loss
y_predicted = model(X)
loss = criterion(y_predicted, y)
# Backward pass and update
loss.backward()
optimizer.step()
# zero grad before new step
optimizer.zero_grad()
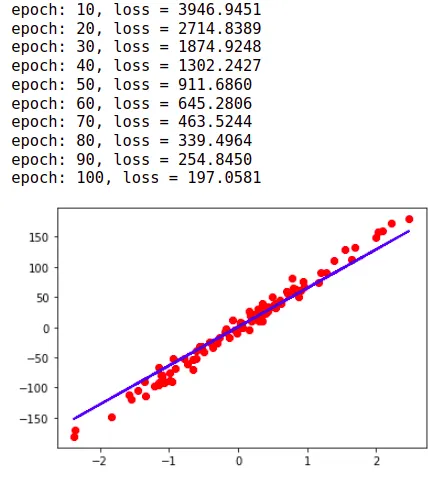
if (epoch+1) % 10 == 0:
print(f'epoch: {epoch+1}, loss = {loss.item():.4f}')
# Plot
predicted = model(X).detach().numpy() # model에 행하는 연산이 graph에 반영되면 안되기 때문에 detach() 함수를 사용한다
plt.plot(X_numpy, y_numpy, 'ro')
plt.plot(X_numpy, predicted, 'b')
plt.show()
Python
복사
2. Logistic Regression
import torch
import torch.nn as nn
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 0) Prepare data
bc = datasets.load_breast_cancer()
X, y = bc.data, bc.target
n_samples, n_features = X.shape
# sklearn의 train/test 데이터셋을 나눠주는 모듈 활용
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)
# scale : Batch Normalization의 역할을 한다. (mean = 0, standard_dev = 0)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# numpy array -> torch tensor
X_train = torch.from_numpy(X_train.astype(np.float32))
X_test = torch.from_numpy(X_test.astype(np.float32))
y_train = torch.from_numpy(y_train.astype(np.float32))
y_test = torch.from_numpy(y_test.astype(np.float32))
y_train = y_train.view(y_train.shape[0], 1)
y_test = y_test.view(y_test.shape[0], 1)
# 1) Model
# Linear model f = wx + b , sigmoid at the end
class Model(nn.Module):
def __init__(self, n_input_features):
super(Model, self).__init__()
self.linear = nn.Linear(n_input_features, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = Model(n_features)
# 2) Loss and optimizer
num_epochs = 100
learning_rate = 0.01
criterion = nn.BCELoss() # Binary Cross Entropy Loss
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 3) Training loop
for epoch in range(num_epochs):
# Forward pass and loss
y_pred = model(X_train)
loss = criterion(y_pred, y_train)
# Backward pass and update
loss.backward()
optimizer.step()
# zero grad before new step
optimizer.zero_grad()
if (epoch+1) % 10 == 0:
print(f'epoch: {epoch+1}, loss = {loss.item():.4f}')
# evaluation 하는 프로세스가 graph에 포함되면 안된다.
with torch.no_grad():
y_predicted = model(X_test)
y_predicted_cls = y_predicted.round()
acc = y_predicted_cls.eq(y_test).sum() / float(y_test.shape[0])
print(f'accuracy: {acc.item():.4f}')
Python
복사

Pytorch에서 제공하는 Loss function, Activation Function, Optimization Function를 확인하고 싶다면 아래 첨부한 파이토치 공식홈페이지를 참고하자.


