Investigating the Role of Image Retrieval for Visual Localization - An exhaustive benchmark
이 논문을 통해 image retrieval이 visual localization에서 어떠한 영향을 미치는 알아보도록 하자!
VL에서 Image Retrieval을 왜 쓰는 건가요??
1.
주어진 이미지의 pose를 추정할 때 근사치로 사용할 수 있습니다.
2.
주어진 query 이미지로부터 scene에 어떤 부분인지 판단할 수 있게 해줍니다.
Visual Localization Metric
는 camera rotation을, 는 camera position을 나타낸다.
따라서 각 컴포넌트의 error를 아래와 같이 표현 할 수 있다.
주어진 error threshold satisfies with
에서 얼마나 많은 이미지가 localized 되었는지 평가한다. (%로 표현) 총 3가지로 나뉜다.
•
low
•
medium
•
high
사용하는 Image Retrieval method 비교
총 4가지가 있으며 Global한 Image Representation을 표현하는 방법들이다.
각 방법들에 대한 자세한 설명은 따로 포스팅을 통해 언급하도록 하겠다.
•
DenseVLAD
•
NetVLAD
•
AP-GeM
•
DELG
이 논문에서는 image retrieval을 이용하여 visual localization을 해결하기 위해 크게 3가지의 방법을 제시한다.
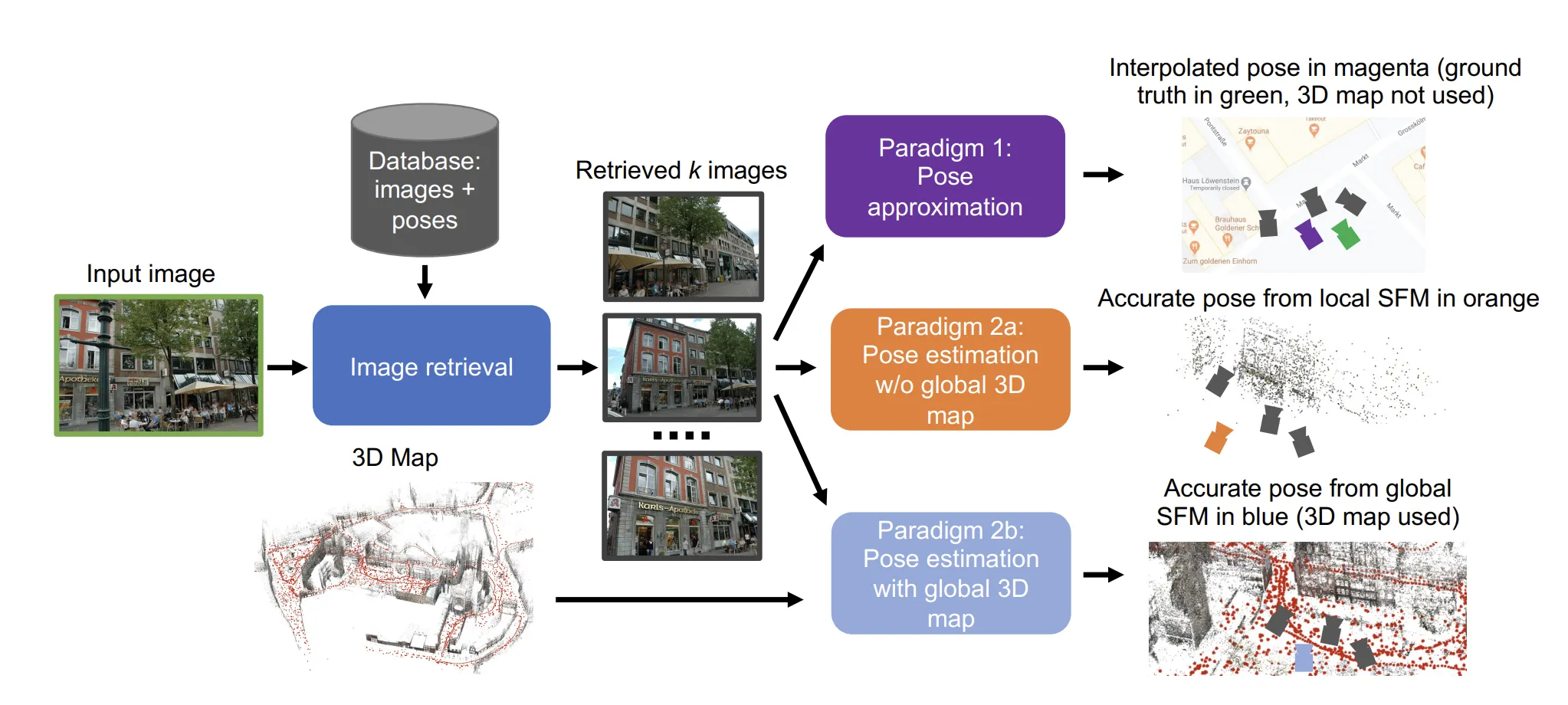
1. Pose Approximation
Image retrieval 방법을 통해 얻 Query Image와 유사한 이미지로 판명한 개의 Database Images를 이용하여 query pose를 추정하는 방식이다.
•
정확한 포즈 추정이 필요없는 경우 (대략적인 위치 판별)에 사용하는 방법이다.
•
Database의 이미지가 query 이미지와 가능한 유사해야하며 그렇다고 너무 변화가 없는 이미지들로만 구성하면 안된다. (ex. 시점 변화)
camera pose를 로 표현한다면 query pose는 아래와 같이 나타낼 수 있다.
( 인 카메라 position, 인 카메라 orientation, 는 top 번째 database pose )
이 때 이 weight 값을 어떻게 설정하는가에 따라 pose 값이 바뀐다. 크게 3가지의 방법이 있다.
( 와 는 각각 query와 database의 global image-level descriptor를 말한다.)
•
EWB (Equal Weighted barycenter) : 로 두어 모든 DB 이미지가 같은 weight를 가진다.
•
BDI (Bary-centric descriptor interpolation) :
를 최소화하는 과정을 거쳐 최적의 weight를 구한다.
•
CSI (Cosine similarity) : 로 설정하여,
두 벡터의 Cosine similarity가 높을 수록 더 높은 weight를 준다.
Results for Pose Approximation
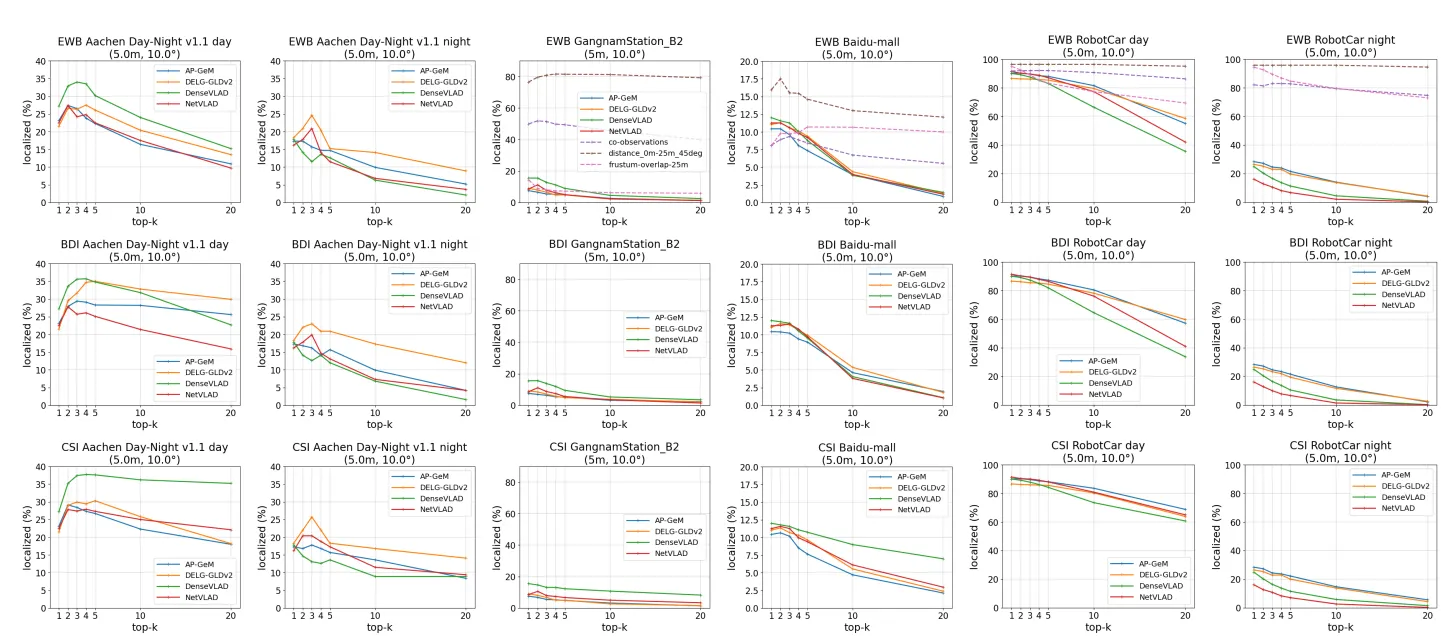
•
성능이 좋지 않다. low 인 제일 쉬운 threshold에 대해서도 낮은 accuracy를 보인다.
•
단순한 CSI 방법의 성능이 복잡한 BDI 방법의 성능보다 좋으며, EWB 방법이 제일 별로이다.
•
개의 retrieved image를 사용할 경우 관련이 적은 이미지들이 들어오게 되고 이는 성능 저하로 이어진다.
2. Pose Estimation with local 3D Map
Image retrieval 방법을 통해 얻은 이미지만을 사용하며 query image와 retrieved image 사이의 relative pose를 측정하여 pose를 측정한다.
•
pose를 알고 있는 retrieved images를 이용하여 즉석에서 3D map을 만든다. (local SFM)
•
PnP + RANSAC을 통해 query image를 3D map에서 표현할 수 있다.
•
local SFM을 위해서는 이미지들이 몇가지 조건을 만족해야 한다.
◦
상위 개의 이미지 중 2개 미만의 이미지가 쿼리 이미지와 동일한 위치를 나타내면 안된다.
◦
retrieved images 사이 시점 변화가 너무 커서는 안된다.
◦
retrieved images 사이 거리(baseline)이 너무 커서 triangulate를 못하게 되면 안된다.
•
정리하면, query image와 같은 scene을 바라보되, 다양한 시점으로 바라보는 이미지들을 retrieval 해야한다. (굉장히 까다롭네….)
Results for Pose Estimation with local SFM
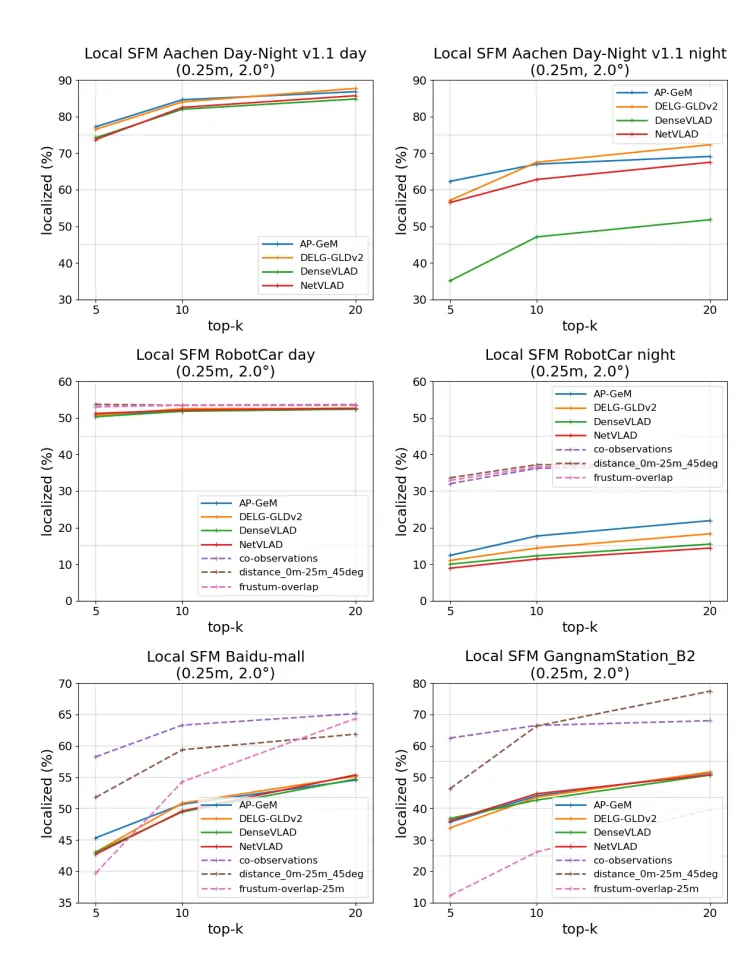
•
RobotCar night 와 Aachen (day and night) 데이터셋에서 AP-GeM과 DELG가 Netvlad와 DenseVLAD 대비 더 좋은 성능을 보여준다.
•
AP-GeM이 강한 조명 환경에서 얻은 데이터를 이용해 학습하여서 제일 좋은 성능을 보여준다.
•
Learned Descriptor를 사용한 모델이 낮-밤 변화에 더 강인하게 동작한다.
•
많은 이미지들을 retrieve 하는 것이 더 나은 local map을 만들게 하고, 더 높은 성능을 보인다.
•
하지만, 너무 많이 넣으면 관련 없는 이미지를 넣게 되고, 실행시간 또한 길어진다 → 최적의 찾자!
•
저자 피셜 일 때 가장 좋다고 하는데…. 다른 데이터셋에 대해서는 다를 수도 있다.
3. Pose Estimation with a global 3D map
database 이미지들을 통해 SFM 모델을 만들고, database 이미지의 local feature와 map의 3D point간의 2D-3D Correspondence와 query 이미지 - top ranked 이미지간의 2D-2D matching을 통해 pose를 추정한다.
•
미리 제작된 global 3D map을 포함하고 있어야 한다. → 많은 메모리 사용
•
이론적으로는 한 개의 관계된 이미지만 얻는것만으로도 충분하지만, 관련있는 이미지들을 더 얻는 것이 정확한 포즈 추정에 도움이 된다.
•
하지만 너무 많으면, 노이즈나 실행시간에 문제를 줄수 있으니 적당량으로 조절하자!
Results for Pose Estimation with global SFM
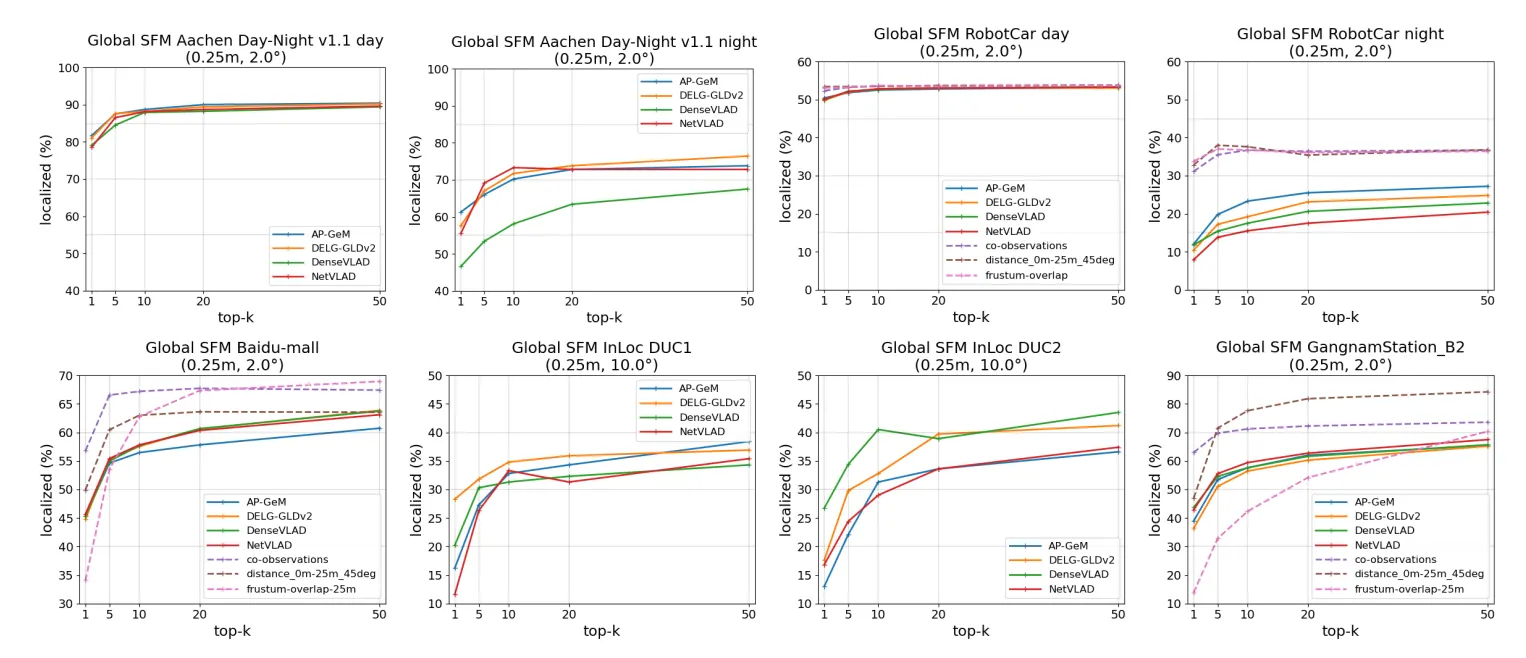
•
learned descriptor를 사용한 AP-GeM과 DELG가 night 이미지에 대해서 높은 성능을 보여준다.
•
InLoc DUC2 데이터셋에 대해서는 DenseVLAD가 다른 방법들 보다 성능이 좋다!? (헐랭)
•
InLoc (indoor dataset) 에서는 DELG가 제일 좋은 성능을 보인다.
◦
InLoc datasets은 반복적인 구조물들이 많다. 따라서 트레이닝 이미지들이 비슷한 양상을 띈다.
따라서 이런 데이터셋에 대해서는 local detail을 잘 캡쳐하는 것이 global한 것보다 더 중요하며,
이 때문에 DenseVLAD 와 DELG 가 성능이 더 높게 나온다….!
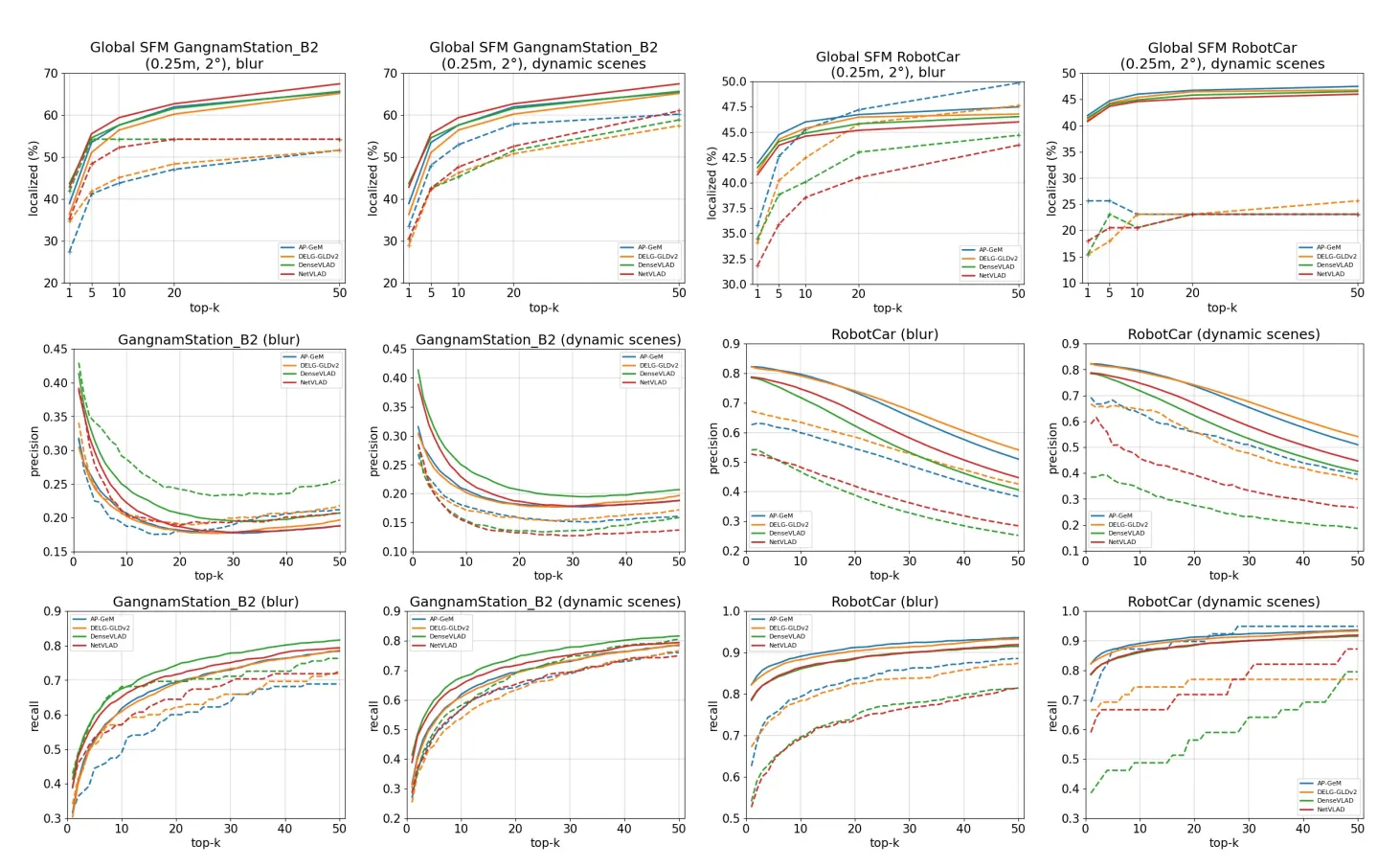
Blur하고 Dynamic한 Scene에서의 성능
blur한 상황: 카메라가 빠르게 움직이는 경우에 발생한다.
Dynamic한 상황: 자동차, 사람과 같은 동적 객체가 scene에 포함되는 경우 발생한다.