
일상 생활에서 우리는 어떠한 현상을 정확히 설명할 수 없기 때문에 확률분포로써 현상을 설명하곤 한다….
또한 우리 주변에 무수히 많은 노이즈가 존재하기 때문에 Randomness에 대해서도 고려할 필요가 있고 이를 위해서라도 확률분포는 너무나도 중요하다!
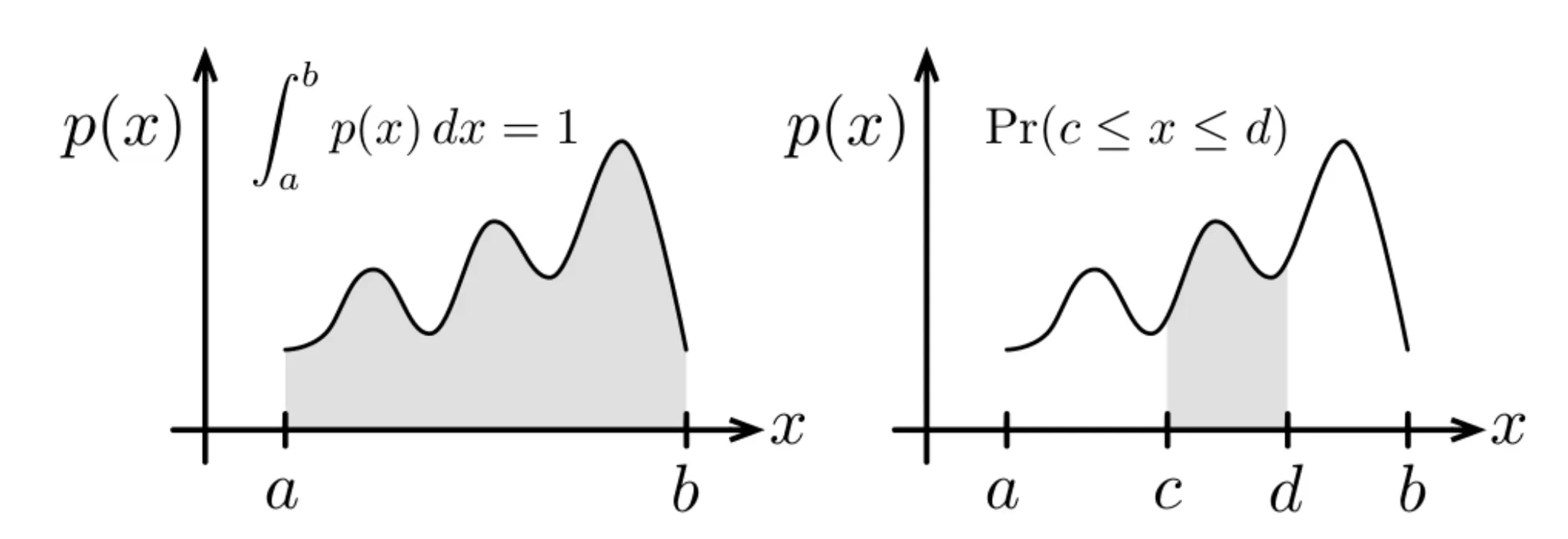
Marginalization (Law of Total Probability)
여러 사건이 동시에 일어날 확률을 의미하는 Joint Distribution은 아래와 같이 정의한다.
이 때, 여러 개의 확률 변수로 이루어진 Joint Distribution에서
한 가지 변수에 대해서만 확률 값을 추정하고 싶다면 어떻게 해야 할까?
간단하다! 나머지 변수에 대해 적분하면 된다! 이 것이 Marginalization이다!
식은 아래와 같이 서술할 수 있다!
Bayes’ Rule
위 개념을 이용하여 조건부 확률을 구할 때 식을 유도해 볼 수 있다.
일단, 조건부 확률에 대한 기본 식을 살펴보자,
위 식을 적절히 바꾸면 아래와 같이 표현할 수 있다.
위에 제시한 두 식과 앞서 언급한 Marginalization을 이용하면 아래의 식을 만들어낸다.
이를 이해하기 쉽게 표현한다면, 그 유명한 베이즈 법칙이 완성된다.
향후 다룰 모든 내용은 이 베이즈 법칙을 기반으로 작성된 알고리즘들이다.

추가사항 - 여러개의 변수를 가지는 Bayes’ Rule

Gaussian Distribution
그 중에서도 우리는 가우시안을 주로 사용하곤 하는데… 이는 Central Limit Theorem 때문이다!
동일한 확률분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 정리인데, 결국 많은 양의 데이터를 다루다 보면 필연적으로 가우시안 분포를 닮게 된다는 말씀!
또한 가우시안을 사용하면 Linear Algebra 형태로 쉽게 풀이할 수 있기 때문에 자주 사용된다.
가우시안을 나타내는 식은 아래와 같다. 흔히들 로 나타낸다.
위는 단항 가우시안이고, 실제로 시스템을 설계한다면,multivariate Gaussian을 사용하는 경우가 많다.
이럴 때 로 나타내곤 하며, 평균과 분산은 각각
를 의미한다.
해당하는 식은 아래와 같다.
Gaussian을 Affine Transform하기
이 식은 계~~~~~속 나오게 되는 식이니 꼭 숙지하자.
가우시안이 나오는 한, 칼만 필터가 전개되는 한 꼭 나오더라…!!!
linear Transform은 의 형태를,
Affine Transform은 의 형태를 띄는 변환방법이다.
아래와 같이 두 분포를 정의해보자.
평균의 성질에 따라 아래와 같이 표현되고,
분산의 정의에 따라 아래와 같이 표현된다.
따라서, 가우시안에 대해 Affine Transform을 진행하게 된다면 그대로 Gaussian이 출력 됨을 알 수 있다. → 이건 정말 매우 really 중요한 성질이다. (후에도 계속해서 나옴….)
Bayes Filter
베이즈 필터의 입출력 요소를 간단하게 살펴보자.
주어지는 것 (Given)
•
관측치 요소들 과 Action 요소(외부)
•
관측 모델
•
Action/motion 모델
얻고 싶은 것 (Wanted)
•
동적 시스템의 state
•
state에 대한 Posterior 확률 belief 이다.
베이즈 필터를 유도하기 전 알아야할 가정이 하나있다.
Markov Assumption
만약 우리가 state 에 대해 알고 있다면, 관측치 은 과 독립이다.
우리가 완벽한 관측치와 프로세스 모델을 통해 추정을 하게 된다면, 모든 이전 정보가 현재의 스테이트에 반영되어 있을 것이므로 고려할 필요가 없다는 것이다.
이 조건을 이용한다면, 위 식을 아래의 식으로 변환 할 수 있다.
위에서 제시한, Markov Assumption, Marginalization, Bayes’ rule 등등을 이용하면 베이즈필터를 만들 준비는 끝난 것이다!
이에 대한 유도과정은 아래와 같다.

이를 통해 Bayes Filter는 두가지 단계로 나누어 표현할 수 있다.
•
Prediction step
◦
•
Correction step
◦
Prediction step은 motion model로 생각할 수 있고,
Correction step은 sensor 혹은 observation model을 의미하게 된다.
이에 대해 작성한 수도코드로 작성한 Bayes-filter 알고리즘은 아래와 같다.


