

visual slam과 관련된 좋은 article이 올라와서 읽어보고 중요한 부분을 정리해 업로드 해보겠습니다.
원본을 읽고 싶으시다면 아래 링크로 들어가시면 됩니다


SLAM(Simultaneous Localization and Mapping)은 로보틱스와 이와 궤를 같이 하는 수많은 분야에서 필요로 하는 분야 입니다. 이 문제를 풀기 위해 많은 연구가 진행되고 있고, 아직 완벽히 해결되지 않았습니다!
SLAM이 풀고자 하는 문제는 “로봇이 어디에 있고, 그 주변은 어떤 상황인지, 내가 어떻게 움직여야하는가?” 를 푸는 것 입니다.
이 문제에 답하기 위해 현재까지 많은 방법들이 제시되어 왔고, 다양한 센서들과 알고리즘을 이용해서 문제를 해결 하고 있습니다. 이번 포스트에서는 어떠한 센서들이 사용되고, 어떻게 error를 줄이고 accuracy를 증진시키는지를 파악하고 각 방법마다의 장단점을 알아보도록 하겠습니다.
LiDAR와 비교해보는 Visual SLAM
현재 필드에서 트렌드를 이끄는 SLAM 방법은 Lidar based SLAM과 Vision based SLAM(Camera)가 있습니다. 먼저 라이다 슬램은 2D 혹은 3D Lidar센서를 이용하여 광학 펄스로 목표물을 비춘 뒤 반사된 신호를 측정해 거리를 매핑하는 방식입니다. 주로 indoor Scene 에서는 2D Lidar를 사용하고, Outdoor Scene에서는 3D Lidar를 사용합니다. 이러한 라이다 슬램은 좋은 성능을 내는 센서와 sensor fusion 알고리즘을 통해 가장 정확한 결과를 얻을 수 있고 안정적인 퍼포먼스를 내는 방법입니다. 하지만 이런 장점에도 불구하고 단점 역시 존재합니다.
LiDAR SLAM의 단점
•
라이다가 다루는 data type 때문에 많은 연산량을 요구합니다
•
라이다 관련 하드웨어를 위한 인프라 설치 비용이 현재로썬 매우 비쌉니다.
•
Object detection, sign-board detection과 같은 task를 수행하려면 더 많은 연산량이 필요합니다
•
sementic 정보를 얻기에 부족합니다.
이러한 단점 때문에, Visual SLAM 알고리즘이 각광을 받고 있습니다. 하드웨어 가격이 저렴하고, 지속적으로 알고리즘이 개선되고 있기 때문입니다. 또한 카메라가 상대적으로 적은 연산량을 필요로 하고 카메라로 하여금 다양한 task를 동시에 실행할 수 있어 인기가 많습니다.
그렇다면, 이러한 visual SLAM방법에는 어떤 게 있고, 어떤 특징이 있는지 살펴보도록 하겠습니다.
Visual SLAM의 종류 살펴보기
Visual SLAM은 순차적으로 입력되는 영상을 통해 제공되는 픽셀의 변화량을 통해 카메라의 움직임을 추정하는 것입니다.
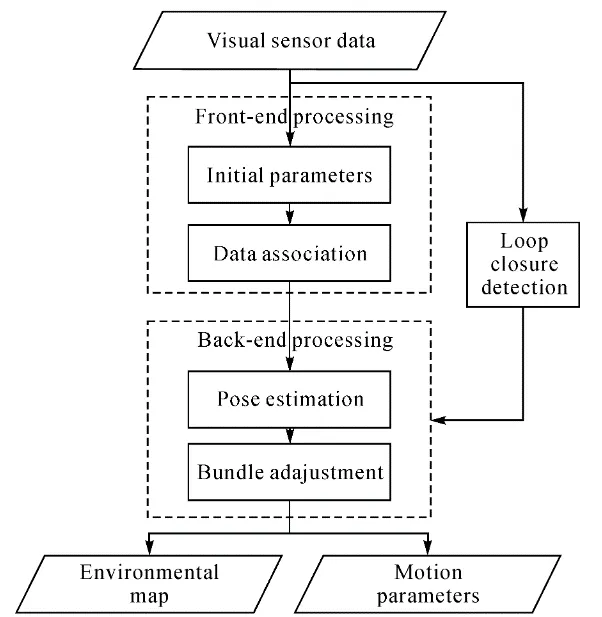
feature based SLAM
feature method는 corner, edges, blobs 등 low level features를 찾고 이를 이용해 물체의 움직임을 판단하는 방법입니다. 한 오브젝트를 바라본 다양한 이미지들 사이의 관계를 파악하기 위해 feature를 이용하며 이를 위해 detection과 descriptor 알고리즘 (SIFT, SURF, ORB)이 생겨났습니다. 이러한 feature들은 translation, rotation, 스케일 변화, viewpoint, 빛세기 등의 성질에 강인합니다. 하지만 feature가 한번 추출되면, feature를 제외한 이미지의 나머지 부분들은 전부 버려지게 됩니다. 이러한 특성은 robust reconstruction을 제공 할수 없는 환경(feature가 적거나 반복적인 환경... 하얀 벽 같이)에서 큰 문제를 일으키게 됩니다.
Direct SLAM
direct method는 연속적인 이미지들 사이를 photogrametric consistency를 이용해 매칭합니다. 이러한 방법에는 DTAM, LSD-SLAM, SVO or DSO 가 있으며, 이러한 방법은 또한 딥러닝의 발전에 힘입어 위의 방식들을 모방하여 동작합니다. 이러한 방법으로 semi-dense한 맵도 만들 수있게 됩니다. 다만 이러한 방법의 경우 시간이 오래 걸리고, GPU가 필요해집니다.
RGB-D SLAM
RGB-D 카메라 센서들 역시 저렴해지고 작기 떄문에 효용성이 높습니다. 이러한 센서는 3D 정보(뎁스 정보)를 실시간으로 제공합니다. 그러나 센서의 범위가 넓지 않기 때문에,(4~5m) 주로 indoor scene에서 사용됩니다. 또한 태양빛에 민감한 특성을 가지고 있습니다.
Event-Camera SLAM
Event-camera의 경우 이미지의 변화(이벤트)를 감지함으로써 무한한 frame rate를 제공할 수 있는 방법입니다. 최근 visual slam task에 탑재되고 있지만, 아직 퍼포먼스가 나오기에는 이릅니다.
인기있는 VSLAM 알고리즘 살펴보기
Deep-Learning VSLAM
앞서 다루었던 geometric한 방법에서는 카메라의 pose를 이미지에서 feature point를 찾고 매칭함으로써 이루어졌다면, deep learning 기반의 방법은 데이터로부터 directly하게 pose를 추정할 수 있습니다.
ORB-SLAM
ORB-SLAM은 real-time SLAM으로써, 카메라 trajectory, 3D reconstruction을 계산하는 monocular, stereo, RGB-D 카메라를 위한 방법입니다. real time에서 loop를 찾고 카메라의 위치를 재배치하며, 작은 indoor환경에서부터 도시 단위의 차량 운행 환경에서도 광범위하게 사용될 수 있는 알고리즘입니다. Bundle Adjustment 기반의 backend 방식이 정확한 trajectory 추정을 가능하게 합니다. 이 방법의 가장 큰 특징들은 feature tracking, mapping, loop closure 그리고 localization 입니다.
ORB-SLAM 3
•
다양한 카메라 센서를 이용해 visual, visual-inertial, multi-map SLAM을 가능하게 합니다
•
feature 기반 tightly-integrated VI SLAM이며, 이러한 방법은 Maximum-A-Posteriori 추정을 이용합니다. 어떠한 환경에서도 사용 가능하며, 기존의 접근방법 대비 2~10배 정확한 성능을 보입니다.
•
multiple-map을 지원합니다. 만약 길을 잃었더라도, 새로운 맵을 생성하여 진행하고 방문했었던 장소에 도달하면 이전 맵들과 결합하는 방식으로 좋지 않은 visual 정보가 들어오는 환경에서도 강인하게 동작할 수 있게 됩니다.
