
Abstract
•
Inertial sensor measurements를 이용해 absolute location을 추정하는 것이다.
•
크게 2단계의 파이프라인을 가지고 있다.
◦
1차 Neural Inertial Navigation(RoNIN)을 이용하여 inertial sensor history를
velocity vector sequence로 바꾼다.
◦
2차 Transformer 기반의 아키텍쳐를 사용하여 velocity vector sequence로부터
디바이스의 위치를 찾는다. (localization)
Introduction
“ 일어나서, 5미터 가량 앞으로 걸어가, 그리고 오른쪽으로 돌고나면 오피스 문을 열 수 있어!
그렇다면 지금 내가 현재 어디인지 맞춰봐!”
이 정도의 정보라면 개인의 위치 추정을 하는데 크게 문제가 없다. 이런 형태로 localization을 해보자!
(사실 이러한 문제를 수능인가…토익이었던가에서 풀었던 것 같다.)
오브젝트의 motion history를 IMU를 이용해 얻는 방법들이 등장하고 있다. → Inertial Navigation
그러나 얻은 motion history를 맵 상에 나타내는 것은 아직 부족한 상태이다. → Inertial localization
이 논문은 inertial navigation을 이용해 IMU sensor data를 velocity vector로 바꾸고, 이를 location으로 mapping하는 알고리즘을 제시한다.
이 과정에서 불확실성이 큰 문제인데, Complex Long sequential data를 인코딩할 수 있는
transformer 구조를 사용함으로써 해결한다.
Inertial Localization Problem
Inertial Localization은 오브젝트를 주어진 환경에서 어디에 위치하고 있는지를 추정하는 테스크이다.
•
Input : sequence of IMU measurements
◦
acceleration (accelerometer)
◦
angular velocity (gyroscope)
◦
magnetic field (compass) - optional
•
Output : 주어진 timestamp에서의 Position estimation
•
Metric : 거리 임계값(1, 2, 4 또는 6m) 내에서 정확한 position 추정의 비율(%),
각도 임계값(20도 또는 40도) 내에서 올바른 velocity 방향의 비율(%)입니다.
•
앞서 진행하는 IL과 별개로 Re-localization task 도 따로 진행한다.
Inertial Localization Dataset
•
53시간의 motion / trajectory 데이터를 포함합니다. (2개의 대학 건물, 하나의 오피스 공간)
•
GT trajectories가 평면도 위에 표현되어 있습니다. 이 때 각 장면은 평평한 바닥에 걸쳐 있으며 위치는 수직 변위 없이 2D Coordinate로 지정됩니다.
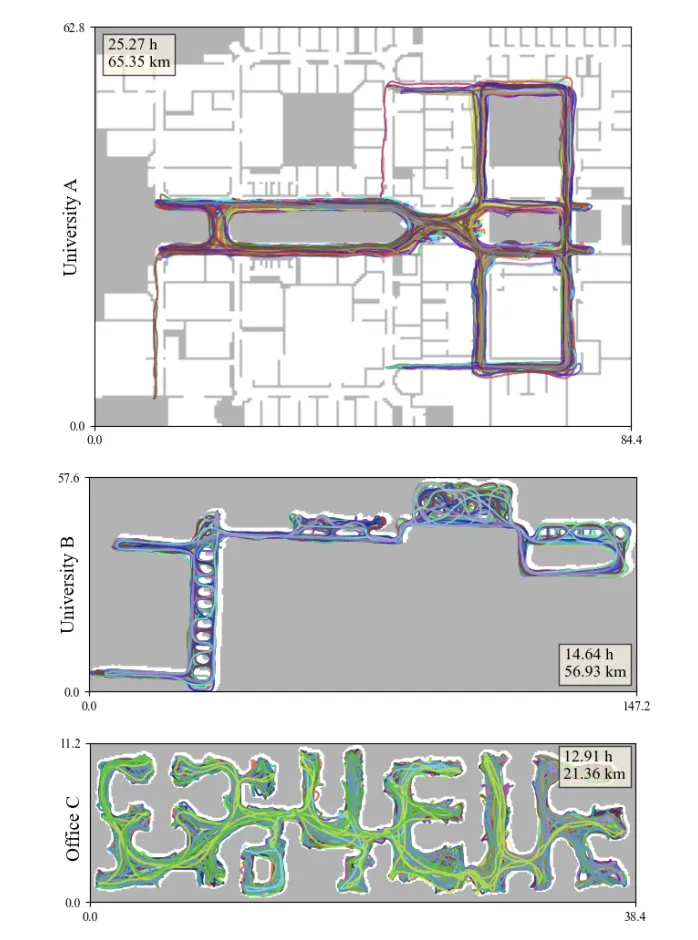
•
스마트폰을 이용하여 데이터를 취득함 → 향후에는 AR 기기를 활용하여 얻을 수 있음
◦
GT motion : handheld 3D Tracking Phone (Google Tango) - Visual-Inertial SLAM
◦
IMU data : 자연스럽게 폰을 들고 다니면서 취득
Tango Area Description Files를 사용하여 GT trajectory를 common coordinate frame에 맞춘 다음
평면도와 수동으로 정렬한다.
IMU 센서 데이터와 GT position은 200Hz의 속도로 기록된다.
•
평균 지속 시간이 13.3분인 궤적 중 6분의 1을 무작위로 Test data로 선택한다. 각 test sequence로부터 무작위로 세 개의 sub-sequences (100m)을 잘라내어서 테스트를 위한 짧은 고정 길이 sequence set을 형성한다.
Model Description
 IMU mesurement → velocity vector → location estimation
IMU mesurement → velocity vector → location estimation 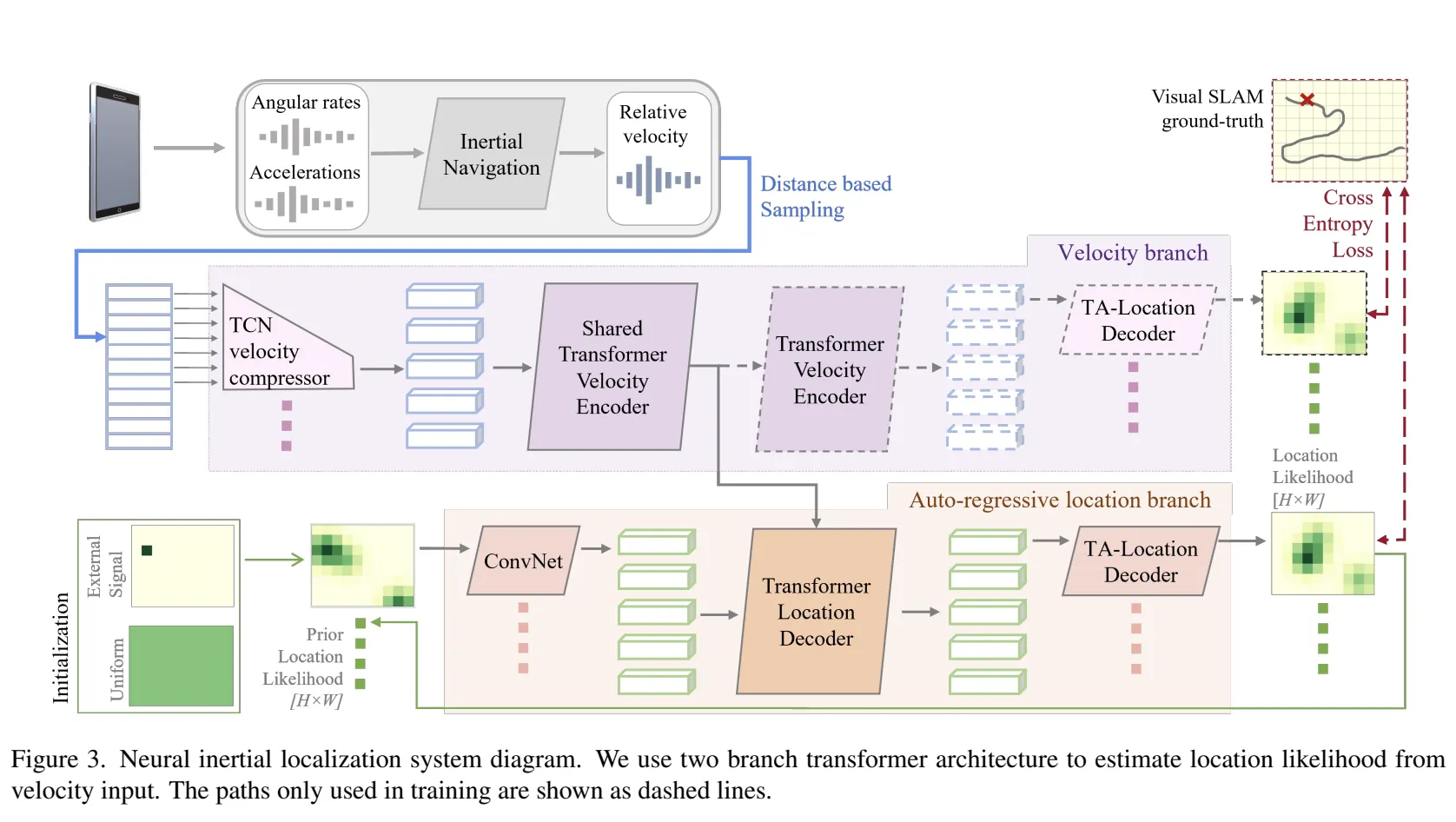
들어가기에 앞서, IMU mesurement → velocity vector 이 과정은 저자가 2020년에 제시한 RoNIN 알고리즘을 이용하여 이미 데이터를 얻었다고 가정하고 진행한다. 관련 논문이 궁금하다면 여기를 눌러 참고하기 바란다.
높은 불확실성(High Uncertainty)이 이 테스크의 가장 큰 문제 이다.
긴 시간의 복잡한 motion data의 불확실성을 줄여야 한다 → Transformer Architecture 사용!
2개로 branch된 Transformer 구조 사용한다.
•
velocity branch
•
Auto-regressive location branch
1. Velocity branch
velocity history을 이용하여 location sequence를 추정한다.
이 과정에 3가지 네트워크 모듈을 사용한다.
TCN-based velocity compressorTransformer는 성능이 좋지만, 메모리를 많이 필요로 합니다. 이에 대응하기 위해서 TCN을 이용하여 velocity sequence의 길이를 10배 압축합니다. 이를 통해 더 긴 motion history를 다룰 수 있습니다.
velocity vectors of length ⇒ -dimensional feature vectors of length
Transformer velocity encoder압축된 velocity vector 를 token으로 사용한다.
Translation-Aware location decoder불확실성을 다루기 위해, Output location은 사이즈를 가지는
2D likelihood map 로 표현이 된다.
2. Auto-regressive location branch
위에서 제시한 velocity branch 에서 추출한 velocity features와 과거 정보, 외부의 position 정보로 부터 얻은 prior location likelihoods를 결합한다.
location branch는 velocity branch와 동일한 구조를 가지지만 크게 2가지 부분이 다르다.
•
TCN-based velocity compressor 대신 ConvNet을 사용하여 크기의 likelihood map을
-dimensional vector로 만듭니다.
•
모든 self-attention layer를 거치고 난 후에 velocity branch로부터 velocity features와 cross-attention을 구합니다.
Inference할 때에는,
1.
velocity feature vector를 얻기 위해 velocity branch를 sliding window 방식으로 evaluate한다.
2.
location branch는 20프레임까지의 location likelihood history를 입력합니다.
3.
3. Training Scheme
두 개의 branch에 대해서 cross-entropy loss를 적용시킨다.
GT-likelihood는 하나의 픽셀 값만 1이고 나머지 픽셀은 0인 형태를 가진다.
4. Synthetic data generation
Transformer 구조는 많은 양의 트레이닝 데이터를 필요로 한다.
충분한 데이터가 실제적으로 존재하지 않기 때문에 synthetic하게 데이터를 더 만들었다.
•
training trajectory의 likelihood map을 계산한다.
•
높은 likelihood 값을 갖는 지역의 쌍을 무작위로 선정한다.
•
smooth하고 높은 likelihood를 갖는 지역을 통과하는 trajectory를 만들기 위해
Optimization 문제를 해결한다
Experimental Results
Limitations and Future Work
2가지의 주요한 실패 요인이 존재한다!
•
열린 공간에서 인간의 움직임은 예측하기 어렵다.
•
반복되거나 대칭적인 환경에서는 위치가 높은 likelihood가 여러 개일 수 있다.
저자가 말하는 future work
•
body motion signal (ex. 문 열기, 손 닦기, 커피 주문하기)을 이용하여 불확실성 제거하는 데 사용
◦
이러한 활동들은 IMU에는 캡쳐되지만, Inertial navigation과 distance-based velocity sampling에서 버려진다. 이러한 정보는 localization에 효과적인 단서를 제공한다.
